| Generative Hierarchical Temporal Transformer for Hand Pose and Action Modeling |
|||
| Yilin Wen1,2,
Hao Pan3,
Takehiko Ohkawa2,
Lei Yang1,4,
Jia Pan1,4,
Yoichi Sato2, Taku Komura1, Wenping Wang5 |
|||
|
1The University of Hong Kong, 2The University of Tokyo, 3Microsoft Research Asia, 4Centre for Garment Production Limited, Hong Kong, 5Texas A&M University |
|||
|
ECCVW 2024 (HANDS Workshop) |
|||
| Abstract | |||
| We present a novel unified framework that concurrently tackles recognition and future prediction for human hand pose and action modeling. Previous works generally provide isolated solutions for either recognition or prediction, which not only increases the complexity of integration in practical applications, but more importantly, cannot exploit the synergy of both sides and suffer suboptimal performances in their respective domains. To address this problem, we propose a generative Transformer VAE architecture to model hand pose and action, where the encoder and decoder capture recognition and prediction respectively, and their connection through the VAE bottleneck mandates the learning of consistent hand motion from the past to the future and vice versa. Furthermore, to faithfully model the semantic dependency and different temporal granularity of hand pose and action, we decompose the framework into two cascaded VAE blocks: the first and latter blocks respectively model the short-span poses and long-span action, and are connected by a mid-level feature representing a sub-second series of hand poses. This decomposition into block cascades facilitates capturing both short-term and long-term temporal regularity in pose and action modeling, and enables training two blocks separately to fully utilize datasets with annotations of different temporal granularities. We train and evaluate our framework across multiple datasets; results show that our joint modeling of recognition and prediction improves over isolated solutions, and that our semantic and temporal hierarchy facilitates long-term pose and action modeling. | |||
| Algorithm overview | |||
 |
|||
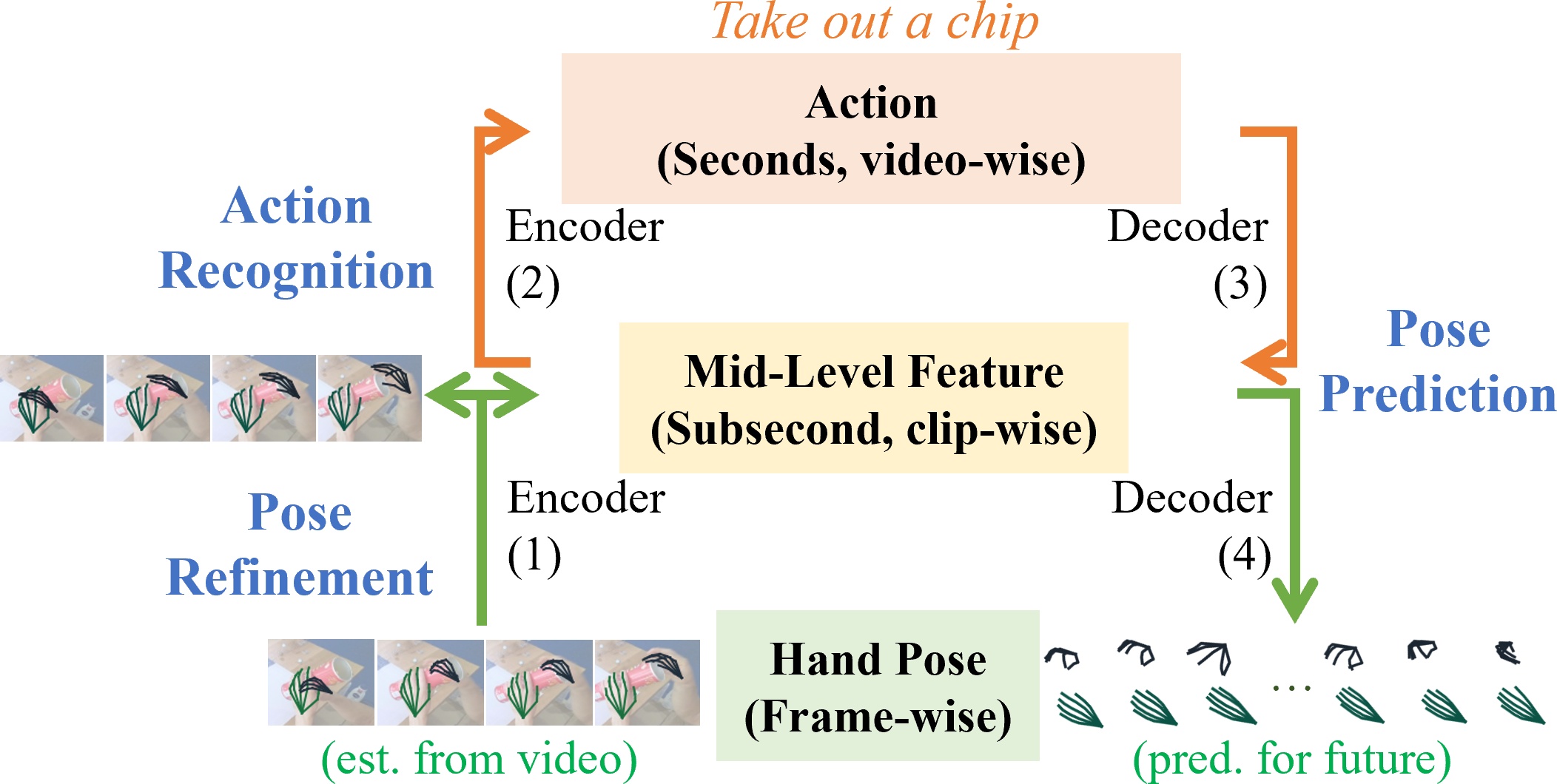
| Jointly modeling recognition and prediction, while following the semantic dependency and temporal granularity for hand pose-action. For recognition, (1)->(2) moves up from short to long spans for input pose refinement and action recognition respectively. For motion prediction, two paths are available: (1)->(4) exploits short-term motion regularity, and (1)->(2)->(3)->(4) enables long-term action-guided prediction. | |||
 |
|||
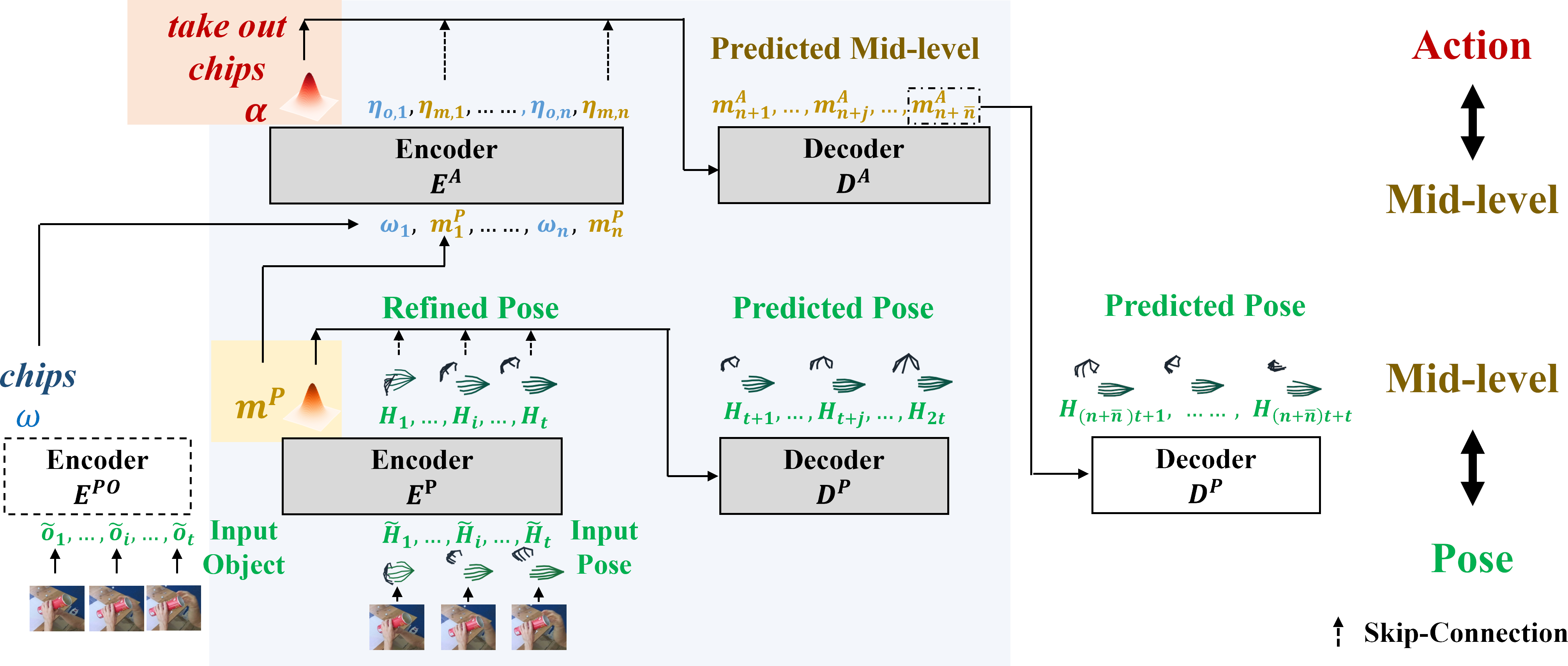
| Overview of our framework. The cascaded P and A (shaded in blue) of G-HTT jointly model recognition and prediction, and faithfully respect the semantic dependency and temporal granularity among pose, mid-level and action. For motion prediction, the decoder DP can decode either mP from the encoder EP for short-term prediction (DP in gray), or from mA via the action block for long-term action-guided prediction (DP in white). | |||
|
|||
| ©Y. Wen. Last update: Sept, 2024. |
